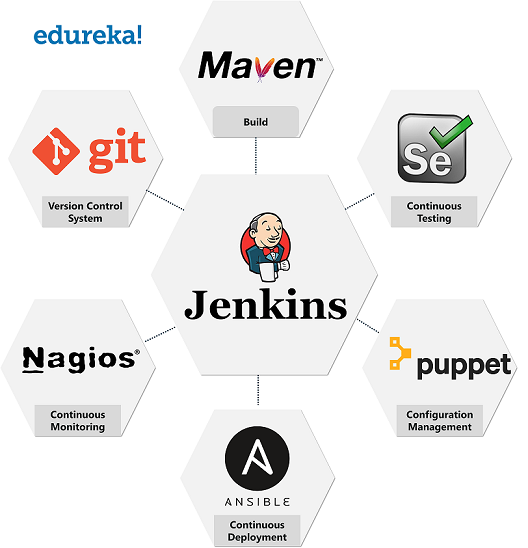
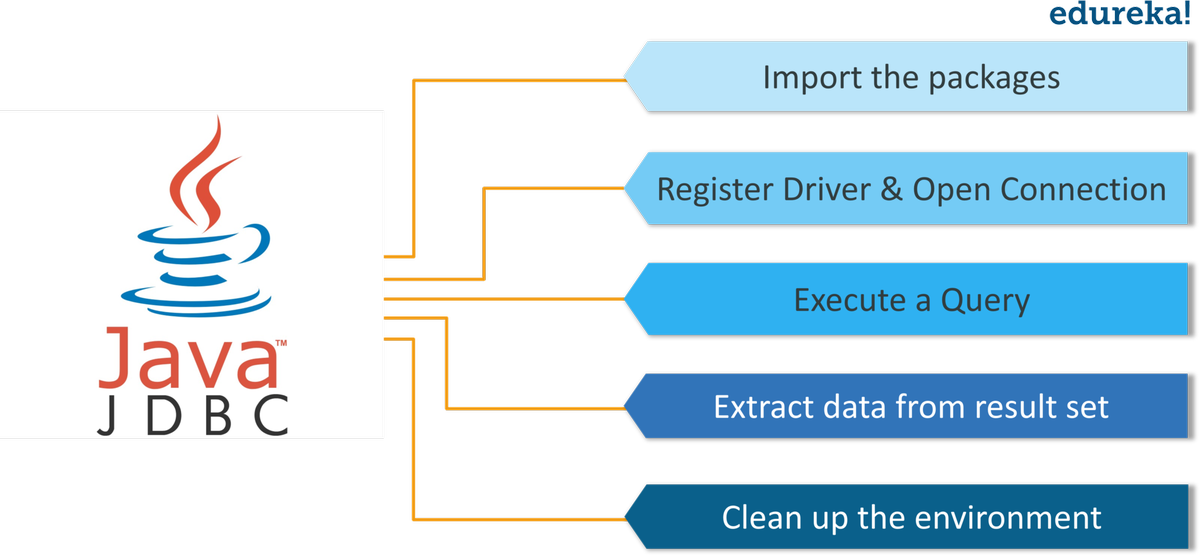
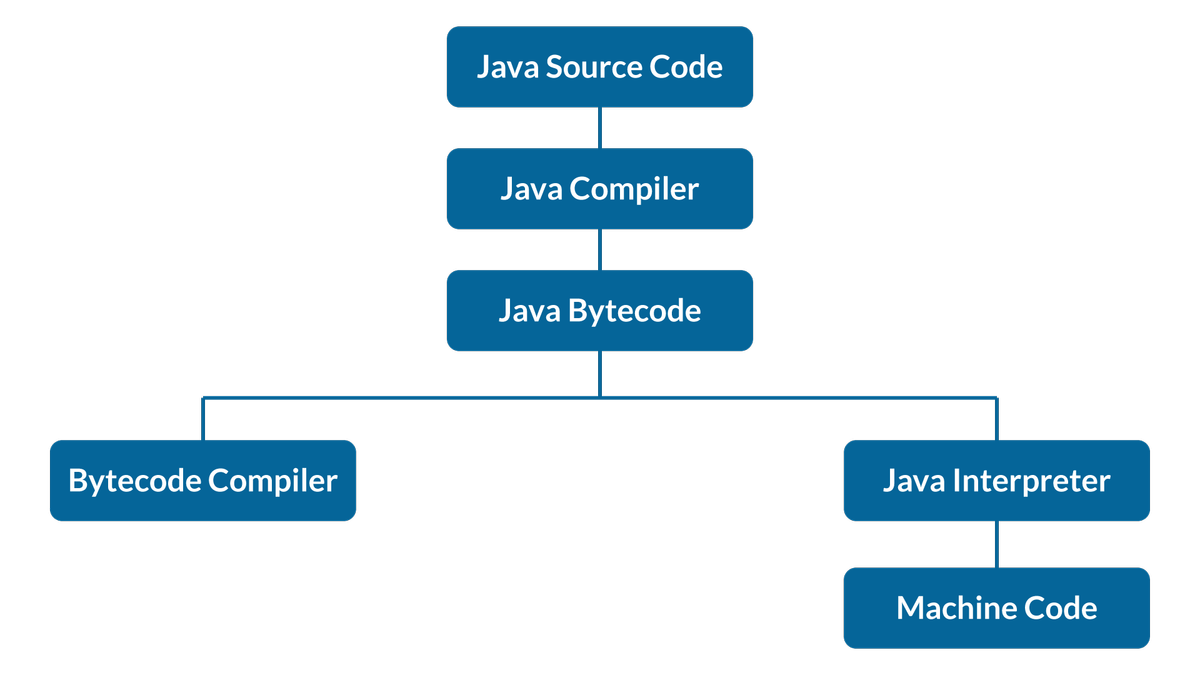
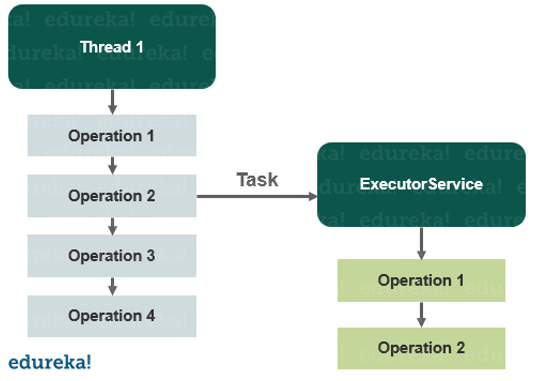
Spark vs Hadoop: Hvilket er det beste Big Data Framework?
Dette blogginnlegget snakker om apache gnist vs hadoop. Det vil gi deg en ide om hvilket som er riktig Big Data-rammeverk å velge i forskjellige scenarier.

Dette blogginnlegget snakker om apache gnist vs hadoop. Det vil gi deg en ide om hvilket som er riktig Big Data-rammeverk å velge i forskjellige scenarier.
Denne bloggen hjelper deg å forstå hvordan du installerer og konfigurerer sbteclipse-plugin med trinnvise instruksjoner for å kjøre Scala-applikasjon i Eclipse IDE.
Dette blogginnlegget forklarer hvorfor du må komme i gang med Apache Spark etter Hadoop og hvorfor lære Spark etter å ha mestret hadoop kan gjøre underverker for karrieren din!
Denne Apache Drill-opplæringen gir deg all informasjonen du trenger for å komme i gang med Apache Drill-søkemotoren, bruk med Hadoop, Big Data & Apache Spark.
Denne Spark Hadoop-bloggen forteller deg alt du trenger å vite om Apache Spark combineByKey. Finn gjennomsnittlig poengsum per student ved hjelp av combineByKey-metoden.
Apache Falcon er en ny datastyringsplattform for Hadoop-økosystemet som forenkler ombordføring av fôrbehandling og feedadministrasjon på hadoop-klynger. Lær hvordan du konfigurerer det.
Denne Apache Spark-bloggen forklarer Gnistakkumulatorer i detalj. Lær bruk av gnistakkumulator med eksempler. Gnistakkumulatorer er som Hadoop Mapreduce-tellere.
Lær alt om Apache Flink og sette opp en Flink-klynge i denne bloggen. Flink støtter sanntids- og batchbehandling og er en må-se Big Data-teknologi for Big Data Analytics.
Dette blogginnlegget diskuterer distribuert caching med kringkastingsvariabler og får deg i gang med å distribuere store verdier effektivt i Spark-programmering.
CCA- og CCP-sertifiseringer fra Cloudera har erstattet CCDH- og CCSHB-eksamen. Denne bloggen forteller deg alt du trenger å vite om de nye sertifiseringene.
Dette blogginnlegget diskuterer stateful transformasjoner med windowsing i Spark Streaming. Lær alt om sporing av data på tvers av grupper ved hjelp av D-Streams.
Dette blogginnlegget diskuterer stateful transformasjoner i Spark Streaming. Lær alt om kumulativ sporing og dyktighet for en Hadoop Spark-karriere.
Hadoop & Big Data-teknologier revolusjonerer helseanalyser. Denne stordata i helsevarebloggen diskuterer hvordan stordataanalyser kan oppgradere medisinsk behandling.
Dette blogginnlegget på Hadoop Streaming er en trinnvis guide for å lære å skrive et Hadoop MapReduce-program i Python for å behandle store mengder Big Data.
Denne bloggen på Big Data Tutorial gir deg en fullstendig oversikt over Big Data, dens egenskaper, applikasjoner samt utfordringer med Big Data.
Denne HDFS opplæringsbloggen vil hjelpe deg med å forstå HDFS eller Hadoop Distribuert filsystem og dets funksjoner. Du vil også utforske kjernekomponentene i korte trekk.
I denne Splunk-veiledningen, forstå forskjellene mellom Splunk vs. ELK vs. Sumo Logic, og finn ut hvilke av disse verktøyene som passer deg best.
I denne bloggen om bruk av Splunk vil du forstå hvordan Domino's Pizza brukte Splunk for å få innsikt i forbrukeratferd. Og formulere forretningsstrategiene.
Denne opplæringen er en trinnvis guide for å installere Hadoop-klyngen og konfigurere den på en enkelt node. Alle installasjonstrinnene for Hadoop er for CentOS-maskinen.
Denne bloggen snakker om de forskjellige HDFS-kommandoene som fsck, copyFromLocal, expunge, cat etc. som brukes til å administrere Hadoop File System.